Which Strand of Dna is Synthesized Continuously
As discussed in Chapter 3, DNA replication is a semiconservative process in which each parental strand serves as a template for the synthesis of a new complementary daughter strand. The central enzyme involved is DNA polymerase, which catalyzes the joining of deoxyribonucleoside 5′-triphosphates (dNTPs) to form the growing DNA chain. However, DNA replication is much more complex than a single enzymatic reaction. Other proteins are involved, and proofreading mechanisms are required to ensure that the accuracy of replication is compatible with the low frequency of errors that is needed for cell reproduction. Additional proteins and specific DNA sequences are also needed both to initiate replication and to copy the ends of eukaryotic chromosomes.
DNA Polymerases
DNA polymerase was first identified in lysates of E. coli by Arthur Kornberg in 1956. The ability of this enzyme to accurately copy a DNA template provided a biochemical basis for the mode of DNA replication that was initially proposed by Watson and Crick, so its isolation represented a landmark discovery in molecular biology. Ironically, however, this first DNA polymerase to be identified (now called DNA polymerase I) is not the major enzyme responsible for E. coli DNA replication. Instead, it is now clear that both prokaryotic and eukaryotic cells contain several different DNA polymerases that play distinct roles in the replication and repair of DNA.
The multiplicity of DNA polymerases was first revealed by the isolation of a mutant strain of E. coli that was deficient in polymerase I (Figure 5.1). Cultures of E. coli were treated with a chemical (a mutagen) that induces a high frequency of mutations, and individual bacterial colonies were isolated and screened to identify a mutant strain lacking polymerase I. Analysis of a few thousand colonies led to the isolation of the desired mutant, which was almost totally defective in polymerase I activity. Surprisingly, the mutant bacteria grew normally, leading to the conclusion that polymerase I is not required for DNA replication. On the other hand, the mutant bacteria were extremely sensitive to agents that damage DNA (e.g., ultraviolet light), suggesting that polymerase I is involved primarily in the repair of DNA damage rather than in DNA replication per se.

Figure 5.1
Isolation of a mutant deficient in polymerase I. A culture of E. coli was treated with a chemical mutagen, and individual bacterial colonies were isolated by growth on semisolid medium. Several thousand colonies were then cultured and screened to identify (more...)
The conclusion that polymerase I is not required for replication implied that E. coli must contain other DNA polymerases, and subsequent experiments led to the identification of two such enzymes, now called DNA polymerases II and III. The potential roles of these enzymes were investigated by the isolation of appropriate mutants. Strains of E. coli with mutations in polymerase II were found to grow and otherwise behave normally, so the role of this enzyme in the cell is unknown. Temperature-sensitive polymerase III mutants, however, were unable to replicate their DNA at high temperature, and subsequent studies have confirmed that polymerase III is the major replicative enzyme in E. coli.
It is now known that, in addition to polymerase III, polymerase I is also required for replication of E. coli DNA. The original polymerase I mutant was not completely defective in that enzyme, and later experiments showed that the residual polymerase I activity in this strain plays a key role in the replication process. The replication of E. coli DNA thus involves two distinct DNA polymerases, the specific roles of which are discussed below.
Eukaryotic cells contain five DNA polymerases: α, β, γ, δ, and ε. Polymerase γ is located in mitochondria and is responsible for replication of mitochondrial DNA. The other four enzymes are located in the nucleus and are therefore candidates for involvement in nuclear DNA replication. Polymerases α, δ, and ε are most active in dividing cells, suggesting that they function in replication. In contrast, polymerase β is active in nondividing and dividing cells, suggesting that it may function primarily in the repair of DNA damage.
Two types of experiments have provided further evidence addressing the roles of polymerases α, δ, and ε in DNA replication. First, replication of the DNAs of some animal viruses, such as SV40, can be studied in cell-free extracts. The ability to study replication in vitro has allowed direct identification of the enzymes involved, and analysis of such cell-free systems has shown that polymerases α and δ are required for SV40 DNA replication. Second, polymerases α, δ, and ε are found in yeasts as well as in mammalian cells, enabling the use of the powerful approaches of yeast genetics (see Chapter 3) to test their biological roles directly. Such studies indicate that yeast mutants lacking any of these three DNA polymerases are unable to proliferate, implying a critical role for polymerase ε as well as for α and δ. However, further studies have shown that the essential function of polymerase ε in yeast does not require its activity as a replicative DNA polymerase. Thus, polymerases α and δ appear to be sufficient for DNA replication both in cell-free systems and in yeast, so the role of polymerase ε remains to be established.
All known DNA polymerases share two fundamental properties that carry critical implications for DNA replication (Figure 5.2). First, all polymerases synthesize DNA only in the 5′ to 3′ direction, adding a dNTP to the 3′ hydroxyl group of a growing chain. Second, DNA polymerases can add a new deoxyribonucleotide only to a preformed primer strand that is hydrogen-bonded to the template; they are not able to initiate DNA synthesis de novo by catalyzing the polymerization of free dNTPs. In this respect, DNA polymerases differ from RNA polymerases, which can initiate the synthesis of a new strand of RNA in the absence of a primer. As discussed later in this chapter, these properties of DNA polymerases appear critical for maintaining the high fidelity of DNA replication that is required for cell reproduction.
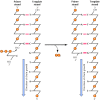
Figure 5.2
The reaction catalyzed by DNA polymerase. All known DNA polymerases add a deoxyribonucleoside 5′-triphosphate to the 3′ hydroxyl group of a growing DNA chain (the primer strand).
The Replication Fork
DNA molecules in the process of replication were first analyzed by John Cairns in experiments in which E. coli were grown in the presence of radioactive thymidine, which allowed subsequent visualization of newly replicated DNA by autoradiography (Figure 5.3). In some cases, complete circular molecules in the process of replicating could be observed. These DNA molecules contained two replication forks, representing the regions of active DNA synthesis. At each fork the parental strands of DNA separated and two new daughter strands were synthesized.

Figure 5.3
Replication of E. coli DNA. (A) An autoradiograph showing bacteria that were grown in [3H]thymidine for two generations to label the DNA, which was then extracted and visualized by exposure to photographic film. (B) This schematic illustrates the two (more...)
The synthesis of new DNA strands complementary to both strands of the parental molecule posed an important problem to understanding the biochemistry of DNA replication. Since the two strands of double-helical DNA run in opposite (antiparallel) directions, continuous synthesis of two new strands at the replication fork would require that one strand be synthesized in the 5′ to 3′ direction while the other is synthesized in the opposite (3′ to 5′) direction. But DNA polymerase catalyzes the polymerization of dNTPs only in the 5′ to 3′ direction. How, then, can the other progeny strand of DNA be synthesized?
This enigma was resolved by experiments showing that only one strand of DNA is synthesized in a continuous manner in the direction of overall DNA replication; the other is formed from small, discontinuous pieces of DNA that are synthesized backward with respect to the direction of movement of the replication fork (Figure 5.4). These small pieces of newly synthesized DNA (called Okazaki fragments after their discoverer) are joined by the action of DNA ligase, forming an intact new DNA strand. The continuously synthesized strand is called the leading strand, since its elongation in the direction of replication fork movement exposes the template used for the synthesis of Okazaki fragments (the lagging strand).

Figure 5.4
Synthesis of leading and lagging strands of DNA. The leading strand is synthesized continuously in the direction of replication fork movement. The lagging strand is synthesized in small pieces (Okazaki fragments) backward from the overall direction of (more...)
Although the discovery of discontinuous synthesis of the lagging strand provided a mechanism for the elongation of both strands of DNA at the replication fork, it raised another question: Since DNA polymerase requires a primer and cannot initiate synthesis de novo, how is the synthesis of Okazaki fragments initiated? The answer is that short fragments of RNA serve as primers for DNA replication (Figure 5.5). In contrast to DNA synthesis, the synthesis of RNA can initiate de novo, and an enzyme called primase synthesizes short fragments of RNA (e.g., three to ten nucleotides long) complementary to the lagging strand template at the replication fork. Okazaki fragments are then synthesized via extension of these RNA primers by DNA polymerase. An important consequence of such RNA priming is that newly synthesized Okazaki fragments contain an RNA-DNA joint, the discovery of which provided critical evidence for the role of RNA primers in DNA replication.

Figure 5.5
Initiation of Okazaki fragments with RNA primers. Short fragments of RNA serve as primers that can be extended by DNA polymerase.
To form a continuous lagging strand of DNA, the RNA primers must eventually be removed from the Okazaki fragments and replaced with DNA. In E. coli, RNA primers are removed by the combined action of RNase H, an enzyme that degrades the RNA strand of RNA-DNA hybrids, and polymerase I. This is the aspect of E. coli DNA replication in which polymerase I plays a critical role. In addition to its DNA polymerase activity, polymerase I acts as an exonuclease that can hydrolyze DNA (or RNA) in either the 3′ to 5′ or 5′ to 3′ direction. The action of polymerase I as a 5′ to 3′ exonuclease removes ribonucleotides from the 5′ ends of Okazaki fragments, allowing them to be replaced with deoxyribonucleotides to yield fragments consisting entirely of DNA (Figure 5.6). In eukaryotic cells, other exonucleases take the place of E. coli polymerase I in removing primers, and the gaps between Okazaki fragments are filled by the action of polymerase δ. As in prokaryotes, these DNA fragments can then be joined by DNA ligase.
Figure 5.6
Removal of RNA primers and joining of Okazaki fragments. Because of its 5′ to 3′ exonuclease activity, DNA polymerase I removes RNA primers and fills the gaps between Okazaki fragments with DNA. The resultant DNA fragments can then be (more...)
The different DNA polymerases thus play distinct roles at the replication fork (Figure 5.7). In prokaryotic cells, polymerase III is the major replicative polymerase, functioning in the synthesis both of the leading strand of DNA and of Okazaki fragments by the extension of RNA primers. Polymerase I then removes RNA primers and fills the gaps between Okazaki fragments. In eukaryotic cells, however, two DNA polymerases are required to do what in E. coli is accomplished by polymerase III alone. Polymerase α is found in a complex with primase, and it appears to function in conjunction with primase to synthesize short RNA-DNA fragments during lagging strand synthesis. Polymerase δ can then synthesize both the leading and lagging strands, acting to extend the RNA-DNA primers initially synthesized by the polymerase α-primase complex. In addition, polymerase δ can take the place of E. coli polymerase I in filling the gaps between Okazaki fragments following primer removal.

Figure 5.7
Roles of DNA polymerases in E. coli and mammalian cells. The leading strand is synthesized by polymerase III (pol III) in E. coli and by polymerase δ (pol δ) in mammalian cells. In E. coli, lagging strand synthesis is initiated by primase, (more...)
Not only polymerases and primase but also a number of other proteins act at the replication fork. These additional proteins have been identified both by the analysis of E. coli mutants defective in DNA replication and by the purification of the mammalian proteins required for in vitro replication of SV40 DNA. One class of proteins required for replication binds to DNA polymerases, increasing the activity of the polymerases and causing them to remain bound to the template DNA so that they continue synthesis of a new DNA strand. Both E. coli polymerase III and eukaryotic polymerase δ are associated with two types of accessory proteins (sliding-clamp proteins and clamp-loading proteins) that load the polymerase onto the primer and maintain its stable association with the template (Figure 5.8). The clamp-loading proteins (called the γ complex in E. coli and replication factor C [RFC] in eukaryotes) specifically recognize and bind DNA at the junction between the primer and template. The sliding-clamp proteins (β protein in E. coli and proliferating cell nuclear antigen [PCNA] in eukaryotes) bind adjacent to the clamp-loading proteins, forming a ring around the template DNA. The clamp proteins then load the DNA polymerase onto DNA at the primer-template junction. The ring formed by the sliding clamp maintains the association of the polymerase with its template as replication proceeds, allowing the uninterrupted synthesis of many thousands of nucleotides of DNA.

Figure 5.8
Polymerase accessory proteins. (A) The clamp-loading protein (RFC in mammalian cells) binds DNA at the junction between primer and template. The sliding-clamp protein (PCNA in mammalian cells) binds adjacent to the RFC, and DNA polymerase then binds to (more...)
Other proteins unwind the template DNA and stabilize single-stranded regions (Figure 5.9). Helicases are enzymes that catalyze the unwinding of parental DNA, coupled to the hydrolysis of ATP, ahead of the replication fork. Single-stranded DNA-binding proteins (e.g., eukaryotic replication factor A [RFA]) then stabilize the unwound template DNA, keeping it in an extended single-stranded state so that it can be copied by the polymerase.
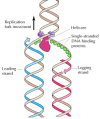
Figure 5.9
Action of helicases and single-stranded DNA-binding proteins. Helicases unwind the two strands of parental DNA ahead of the replication fork. The unwound DNA strands are then stabilized by single-stranded DNA-binding proteins so that they can serve as (more...)
As the strands of parental DNA unwind, the DNA ahead of the replication fork is forced to rotate. Unchecked, this rotation would cause circular DNA molecules (such as SV40 DNA or the E. coli chromosome) to become twisted around themselves, eventually blocking replication (Figure 5.10). This problem is solved by topoisomerases, enzymes that catalyze the reversible breakage and rejoining of DNA strands. There are two types of these enzymes: Type I topoisomerases break just one strand of DNA; type II topoisomerases introduce simultaneous breaks in both strands. The breaks introduced by type I and type II topoisomerases serve as "swivels" that allow the two strands of template DNA to rotate freely around each other so that replication can proceed without twisting the DNA ahead of the fork (see Figure 5.10). Although eukaryotic chromosomes are composed of linear rather than circular DNA molecules, their replication also requires topoisomerases; otherwise, the complete chromosomes would have to rotate continually during DNA synthesis.

Figure 5.10
Action of topoisomerases during DNA replication. (A) As the two strands of template DNA unwind, the DNA ahead of the replication fork is forced to rotate in the opposite direction, causing circular molecules to become twisted around themselves. (B) This (more...)
Type II topoisomerase is needed not only to unwind DNA but also to unravel newly replicated circular DNA molecules that become interwined with each other. In eukaryotic cells, topoisomerase II appears to be involved in mitotic chromosome condensation. In addition, studies of yeast mutants, as well as experiments in Drosophila and mammalian cells, indicate that topoisomerase II is required for the separation of daughter chromatids at mitosis, suggesting that it functions to untangle newly replicated loops of DNA in the chromosomes of eukaryotes.
The enzymes involved in DNA replication act in a coordinated manner to synthesize both leading and lagging strands of DNA simultaneously at the replication fork (Figure 5.11). This task is accomplished by the formation of dimers of the replicative DNA polymerases (polymerase III in E. coli or polymerase δ in eukaryotes), each with its appropriate accessory proteins. One molecule of polymerase then acts in synthesis of the leading strand while the other acts in synthesis of the lagging strand. The lagging strand template is thought to form a loop at the replication fork so that the polymerase subunit engaged in lagging strand synthesis moves in the same overall direction as the other subunit, which is synthesizing the leading strand.
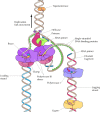
Figure 5.11
Model of the E. coli replication fork. Helicase, primase, and two molecules of DNA polymerase III carry out coordinated synthesis of both the leading and lagging strands of DNA. The lagging strand template is folded so that the polymerase responsible (more...)
The Fidelity of Replication
The accuracy of DNA replication is critical to cell reproduction, and estimates of mutation rates for a variety of genes indicate that the frequency of errors during replication corresponds to only one incorrect base per 109 to 1010 nucleotides incorporated. This error frequency is much lower than would be predicted simply on the basis of complementary base pairing. In particular, the standard configurations of nucleic acid bases are in equilibrium with rare alternative conformations (tautomeric forms) that hydrogen-bond with the wrong partner (e.g., G with T) with a frequency of about one incorrect base per 104 (Figure 5.12). The much higher degree of fidelity actually achieved results largely from the activities of DNA polymerase.

Figure 5.12
Mismatching between rare configurations of nucleic acid bases. In its normal configuration, guanine (G) specifically forms complementary hydrogen bonds (dashed lines) with cytosine (C). However, G occasionally assumes a rare configuration (tautomeric (more...)
One mechanism by which DNA polymerase increases the fidelity of replication is by helping to select the correct base for insertion into newly synthesized DNA. The polymerase does not simply catalyze incorporation of whatever nucleotide is hydrogen-bonded to the template strand. Instead, it actively discriminates against incorporation of a mismatched base, presumably by adapting to the conformation of a correct base pair. The molecular mechanisms responsible for the ability of DNA polymerases to select against incorrect bases are not yet entirely understood, but this selectivity appears to increase the accuracy of replication about a hundredfold, reducing the expected error frequency from 10-4 to approximately 10-6.
The other major mechanism responsible for the accuracy of DNA replication is the proofreading activity of DNA polymerase. As already noted, E. coli polymerase I has 3′ to 5′ as well as 5′ to 3′ exonuclease activity. The 5′ to 3′ exonuclease operates in the direction of DNA synthesis and helps remove RNA primers from Okazaki fragments. The 3′ to 5′ exonuclease operates in the reverse direction of DNA synthesis, and participates in proofreading newly synthesized DNA (Figure 5.13). Proofreading is effective because DNA polymerase requires a primer and is not able to initiate synthesis de novo. Primers that are hydrogen-bonded to the template are preferentially used, so when an incorrect base is incorporated, it is likely to be removed by the 3′ to 5′ exonuclease activity rather than being used to continue synthesis. Such 3′ to 5′ exonuclease activities are also associated with E. coli polymerase III and eukaryotic polymerases δ and ε. The 3′ to 5′ exonucleases of these polymerases selectively excise mismatched bases that have been incorporated at the end of a growing DNA chain, thereby increasing the accuracy of replication by a hundred- to a thousandfold.
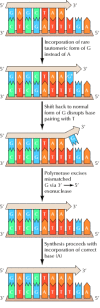
Figure 5.13
Proofreading by DNA polymerase. A rare tautomeric form of G (G*) is incorporated in place of A as a result of mispairing with T on the template strand. The subsequent shift of G back to its normal form disrupts this base pairing, so the 3′ terminal (more...)
The importance of proofreading may explain the fact that DNA polymerases require primers and catalyze the growth of DNA strands only in the 5′ to 3′ direction. When DNA is synthesized in the 5′ to 3′ direction, the energy required for polymerization is derived from hydrolysis of the 5′ triphosphate group of a free dNTP as it is added to the 3′ hydroxyl group of the growing chain (see Figure 5.2). If DNA were to be extended in the 3′ to 5′ direction, the energy of polymerization would instead have to be derived from hydrolysis of the 5′ triphosphate group of the terminal nucleotide already incorporated into DNA. This would eliminate the possibility of proofreading, because removal of a mismatched terminal nucleotide would also remove the 5′ triphosphate group needed as an energy source for further chain elongation. Thus, although the ability of DNA polymerase to extend a primer only in the 5′ to 3′ direction appears to make replication a complicated process, it is necessary for ensuring accurate duplication of the genetic material.
Combined with the ability to discriminate against the insertion of mismatched bases, the proofreading activity of DNA polymerases is sufficient to reduce the error frequency of replication to about one mismatched base per 109. Additional mechanisms (discussed in the section "DNA Repair") act to remove mismatched bases that have been incorporated into newly synthesized DNA, further ensuring correct replication of the genetic information.
Origins and the Initiation of Replication
The replication of both prokaryotic and eukaryotic DNAs starts at a unique sequence called the origin of replication, which serves as a specific binding site for proteins that initiate the replication process. The first origin to be defined was that of E. coli, in which genetic analysis indicated that replication always begins at a unique site on the bacterial chromosome. The E. coli origin has since been studied in detail and found to consist of 245 base pairs of DNA, elements of which serve as binding sites for proteins required to initiate DNA replication (Figure 5.14). The key step is the binding of an initiator protein to specific DNA sequences within the origin. The initiator protein begins to unwind the origin DNA and recruits the other proteins involved in DNA synthesis. Helicase and single-stranded DNA-binding proteins then act to continue unwinding and exposing the template DNA, and primase initiates the synthesis of leading strands. Two replication forks are formed and move in opposite directions along the circular E. coli chromosome.

Figure 5.14
Origin of replication in E. coli. Replication initiates at a unique site on the E. coli chromosome, designated the origin (ori). The first event is the binding of an initiator protein to ori DNA, which leads to partial unwinding of the template. The DNA (more...)
The origins of replication of several animal viruses, such as SV40, have been studied as models for the initiation of DNA synthesis in eukaryotes. SV40 has a single origin of replication (consisting of 64 base pairs) that functions both in infected cells and in cell-free systems. Replication is initiated by a virus-encoded protein (called T antigen) that binds to the origin and also acts as a helicase. A single-stranded DNA-binding protein is required to stabilize the unwound template, and the DNA polymerase α-primase complex then initiates DNA synthesis.
Although single origins are sufficient to direct the replication of bacte-rial and viral genomes, multiple origins are needed to replicate the much larger genomes of eukaryotic cells within a reasonable period of time. For example, the entire genome of E. coli (4 × 106 base pairs) is replicated from a single origin in approximately 30 minutes. If mammalian genomes (3 × 109 base pairs) were replicated from a single origin at the same rate, DNA replication would require about 3 weeks (30,000 minutes). The problem is further exacerbated by the fact that the rate of DNA replication in mammalian cells is actually about tenfold lower than in E. coli, possibly as a result of the packaging of eukaryotic DNA in chromatin. Nonetheless, the genomes of mammalian cells are typically replicated within a few hours, necessitating the use of thousands of replication origins.
The presence of multiple replication origins in eukaryotic cells was first demonstrated by the exposure of cultured mammalian cells to radioactive thymidine for different time intervals, followed by autoradiography to detect newly synthesized DNA. The results of such studies indicated that DNA synthesis is initiated at multiple sites, from which it then proceeds in both directions along the chromosome (Figure 5.15). The replication origins in mammalian cells are spaced at intervals of approximately 50 to 300 kb; thus the human genome has about 30,000 origins of replication. The genomes of simpler eukaryotes also have multiple origins; for example, replication in yeasts initiates at origins separated by intervals of approximately 40 kb.
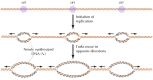
Figure 5.15
Replication origins in eukaryotic chromosomes. Replication initiates at multiple origins (ori), each of which produces two replication forks.
The origins of replication of eukaryotic chromosomes have been studied best in yeasts, in which they have been identified as sequences that can support the replication of plasmids in transformed cells (Figure 5.16). This has provided a functional assay for these sequences, and several such elements (called autonomously replicating sequences, or ARSs) have been isolated. Their role as origins of replication has been verified by direct biochemical analysis, not only in plasmids but also in yeast chromosomal DNA.
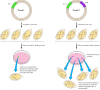
Figure 5.16
Identification of origins of replication in yeast. Both plasmids I and II contain a selectable marker gene (LEU 2) that allows transformed cells to grow on medium lacking leucine. Only plasmid II, however, contains an origin of replication (ARS). The (more...)
Functional ARS elements span about 100 base pairs, including an 11-base-pair core sequence common to many different ARSs (Figure 5.17). This core sequence is essential for ARS function and has been found to be the binding site of a protein complex (called the origin replication complex, or ORC) that is required for initiation of DNA replication at yeast origins. The ORC complex appears to recruit other proteins (including DNA helicases) to the origin, leading to the initiation of replication. The mechanism of initiation of DNA replication in yeasts thus appears similar to that in prokaryotes and eukaryotic viruses; that is, an initiator protein specifically binds to origin sequences.

Figure 5.17
A yeast ARS element. The element contains an 11-base-pair ARS consensus sequence (ACS), which is the specific binding site of the origin replication complex (ORC). Three additional elements (B1, B2, and B3) are individually not essential but together (more...)
In contrast to the well-defined ARS elements in yeasts, much less is known about the nature of replication origins in more complex eukaryotes. However, recent experiments have shown that specific origin sequences are required for initiation of DNA replication in mammalian cells. In addition, proteins related to the yeast ORC proteins have been identified in a variety of eukaryotes, including Drosophila, C. elegans, Arabidopsis, and humans, and shown to be essential for DNA replication. It thus appears likely that the basic mechanism used to initiate DNA replication is conserved in eukaryotic cells.
Telomeres and Telomerase: Replicating the Ends of Chromosomes
Because DNA polymerases extend primers only in the 5′ to 3′ direction, they are unable to copy the extreme 5′ ends of linear DNA molecules. Consequently, special mechanisms are required to replicate the terminal sequences of the linear chromosomes of eukaryotic cells. These sequences (telomeres) consist of tandem repeats of simple-sequence DNA (see Chapter 4). They are replicated by the action of a unique enzyme called telomerase, which is able to maintain telomeres by catalyzing their synthesis in the absence of a DNA template.
Telomerase is a reverse transcriptase, one of a class of DNA polymerases, first discovered in retroviruses (see Chapter 3), that synthesize DNA from an RNA template. Importantly, telomerase carries its own template RNA, which is complementary to the telomere repeat sequences, as part of the enzyme complex. The use of this RNA as a template allows telomerase to generate multiple copies of the telomeric repeat sequences, thereby maintaining telomeres in the absence of a conventional DNA template to direct their synthesis.
The mechanism of telomerase action was initially elucidated in 1985 by Carol Greider and Elizabeth Blackburn during studies of the protozoan Tetrahymena (Figure 5.18). The Tetrahymena telomerase is complexed to a 159-nucleotide-long RNA that includes the sequence 3′-AACCCCAAC-5′. This sequence is complementary to the Tetrahymena telomeric repeat (5′-TTGGGG-3′) and serves as the template for the synthesis of telomeric DNA. The use of this RNA as a template allows telomerase to extend the 3′ end of chromosomal DNA by one repeat unit beyond its original length. The complementary strand can then be synthesized by the polymerase α-primase complex using conventional RNA priming. Removal of the RNA primer leaves an overhanging 3′ end of chromosomal DNA, which can form loops at the ends of eukaryotic chromosomes (see Figure 4.19).
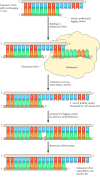
Figure 5.18
Action of telomerase. Telomeric DNA is a simple repeat sequence with an overhanging 3′ end on the newly synthesized leading strand. Telomerase carries its own RNA molecule, which is complementary to telomeric DNA, as part of the enzyme complex. (more...)
Telomerase has been identified in a variety of eukaryotes, and genes encoding telomerase RNAs have been cloned from Tetrahymena, yeasts, mice, and humans. In each case, the telomerase RNA contains sequences complementary to the telomeric repeat sequence of that organism (see Table 4.3). Moreover, the introduction of mutant telomerase RNA genes into yeasts has been shown to result in corresponding alterations of the chromosomal telomeric repeat sequences, directly demonstrating the function of telomerase in maintaining the termini of eukaryotic chromosomes.

Source: https://www.ncbi.nlm.nih.gov/books/NBK9940/